机器之心发布
昨夜,全球最大的 AI 开源社区 Hugging Face 官宣了一项前所未有的决定:自掏腰包为智谱 AI 最新开源的旗舰模型 GLM-5.2 提供长达 6 小时的全球免费算力支持。
这是 Hugging Face 第一次真金白银为国产模型开这种 “专属 VIP 通道”,海外网友纷纷直呼这波 “倒贴” 好!
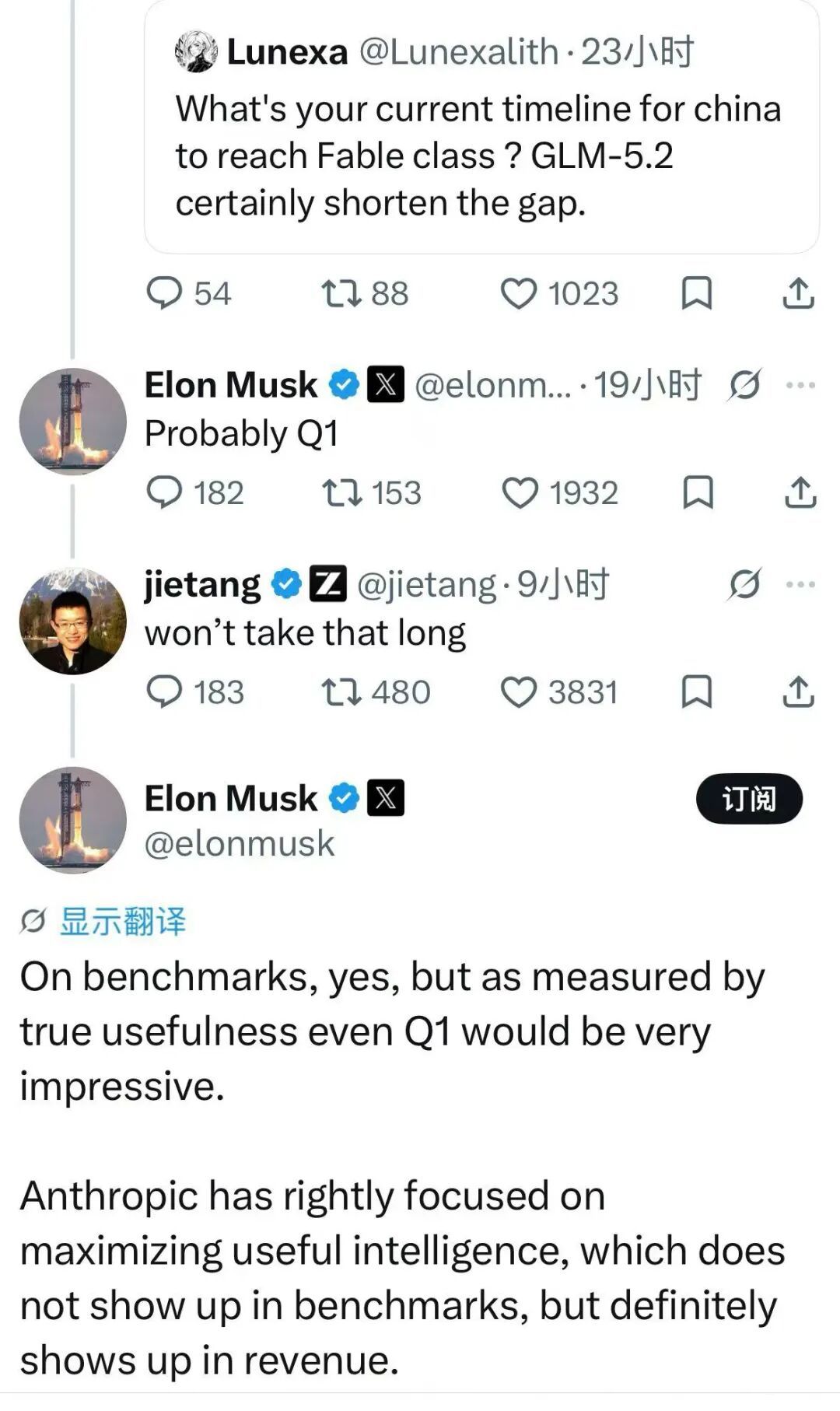
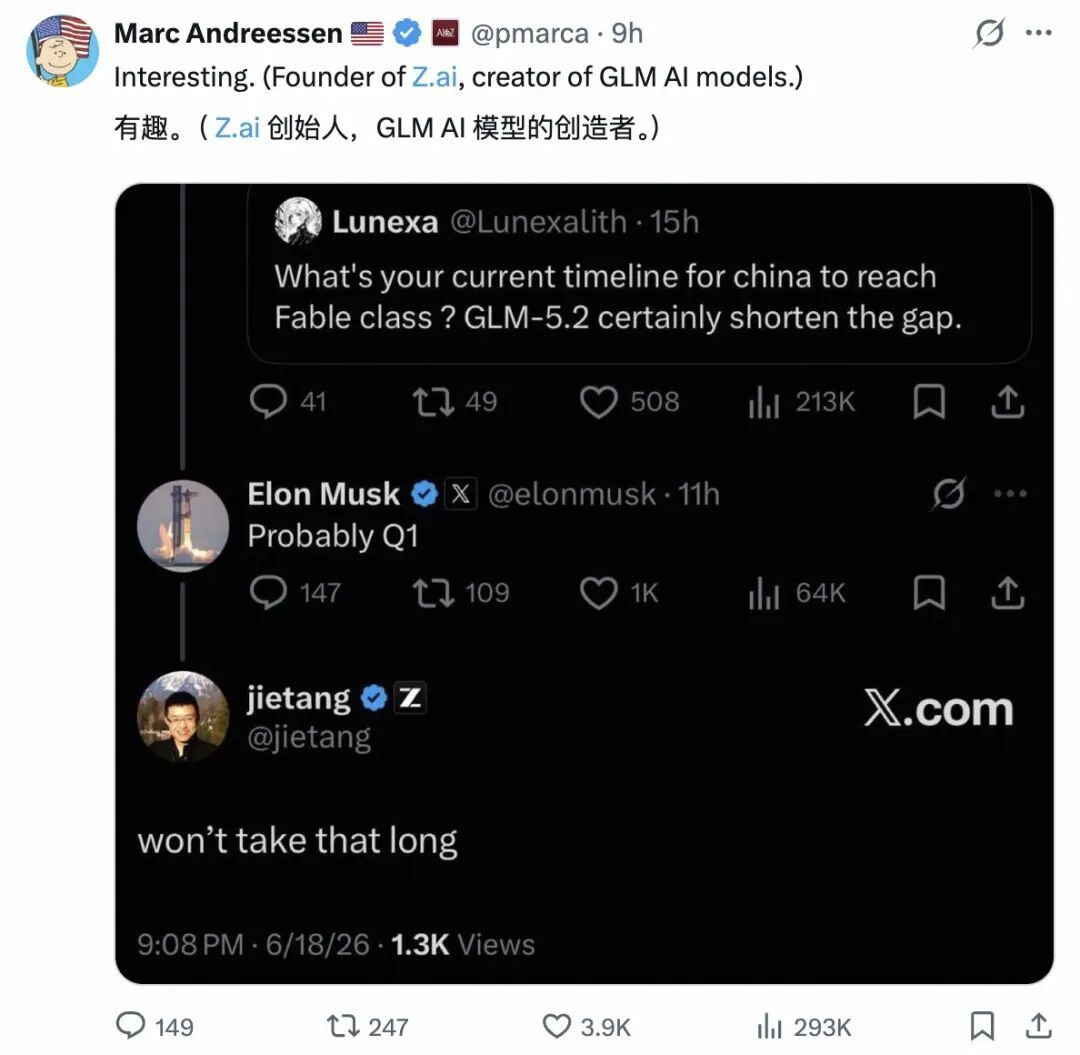
GLM-5.2 的火爆程度仍在持续升温。6 月 18 日,特斯拉创始人马斯克在社交平台回复网友有关 “你目前对中国达到 Fable 级别的预计时间表是什么?GLM-5.2 无疑缩短了差距” 问题时表示,“或许(2027 年)一季度。”
紧接着智谱创始人兼首席科学家唐杰在 X 上隔空喊话:“用不了那么久。”
硅谷顶级风投 a16z 联合创始人 Marc Andreessen 也下场了,Perplexity CEO Aravind Srinivas 同样在 X 上发声。不少国外网友站队,表示马斯克的这波预测 “过于保守”。 #won’t take that long 直接刷屏。
Fable 5 下线,智谱 GLM-5.2 上桌
马斯克的这番判断正值 Anthropic 新模型引发全球讨论之际。
6 月 9 日,美国大模型企业 Anthropic 发布了其有史以来最强 AI 模型 ——Claude Fable 5 和 Claude Mythos 5。6 月 13 日,美国商务部发布出口管制令,要求禁止向 “非美籍用户” 提供,最终 Anthropic 选择了全面下架了两款模型。与出口管制相伴而来的,是美国头部闭源模型访问机制的收紧。前沿闭源模型的访问权,正从过去的账户订阅,逐渐转向更强调身份、地区和资格审核的准入机制。
就在美国对 Anthroic 下达出口管制当天,智谱发文预告了其最强模型 GLM-5.2 即将上线,同时留下了一段意有所指的话:“在一些前沿模型突然变得不可用的时刻,我们选择相信另一条路:前沿智能不应只属于少数人,也不应被少数规则随时收回。它应该开放、可用、可构建,并服务于每一位开发者。”
6 月 17 日,智谱官宣 GLM-5.2 上线,以最宽松的 MIT 协议开源开放,允许免费商用。实现了可用的 1M 稳定上下文长程编程能力量级跃升。
架构层面,GLM-5.2 提出了 IndexShare 机制,每四层稀疏注意力共享同一个 indexer,从而在百万 token 上下文下将每 token 的计算量降低约 2.9 倍。
在 Artificial Analysis 综合榜单上,GLM-5.2 取得 51 分,跻身全球模型前三,并位列开源模型 SOTA;在 FrontierSWE、Terminal-Bench 等代码和长程任务权威基准上,GLM-5.2 与国际顶尖模型 Claude Opus 4.8 的差距收窄至 1%–4%。
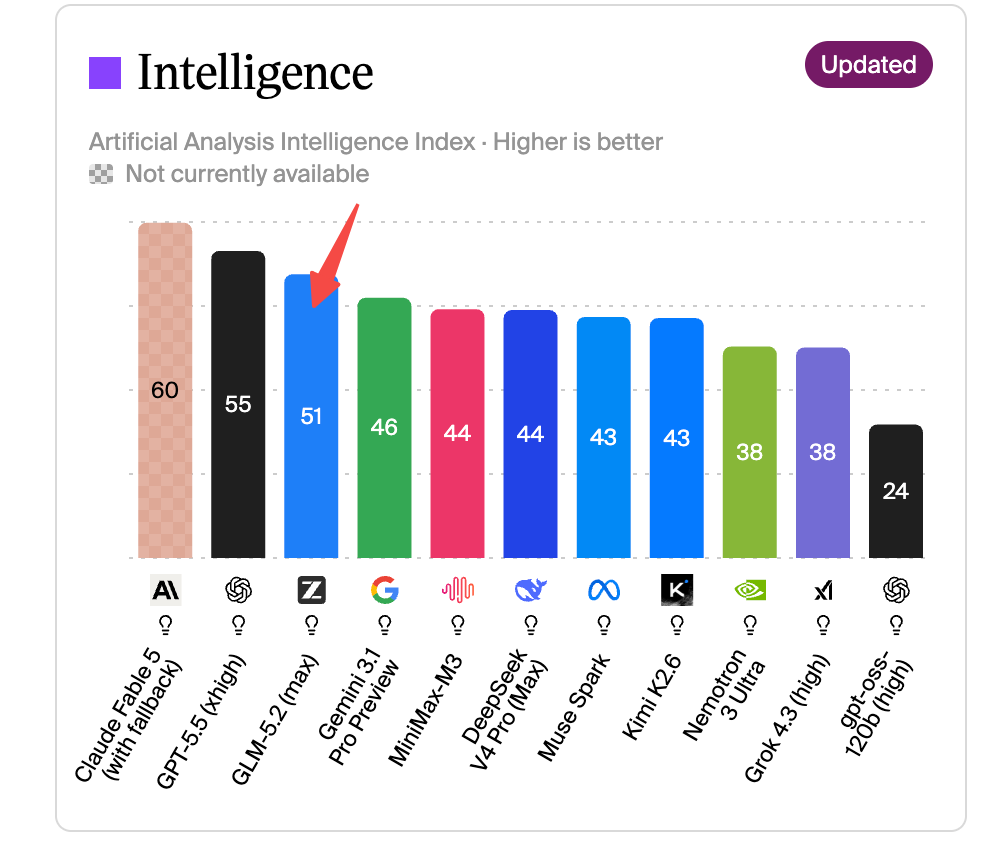
从多个基准评测来看,基本处于比肩 Claude Opus、Fable 5 水平。这也代表开源模型的代码能力第一次达到了行业认可的顶尖闭源模型水平。
中国大模型,跻身模型 “御三家”
在 DeepSeek 出现后一年间,中国大模型企业纷纷拥抱开源,开源模型军团迅速崛起,中国模型迅速拉平了和美国头部模型的差距。
在广受欢迎的 AI 模型访问平台 OpenRouter 上,中国模型的调用量已经从 2024 年底的 1.2% 升至超过 50%,在总量上全面超越美国模型。
不过,调用量反超并不等同于前沿能力全面领先。很长一段时间里,中国模型更多被视为性价比平替、开源补充或单项能力追赶者。
GLM-5.2 的不同之处在于,它试图在智能体编程和长程复杂任务这些过去由 Claude、GPT 等闭源模型占优的场景中,进入同一竞争区间。
在今年春节期间,智谱 GLM-5 模型曾以 Pony Alpha 的隐身身份上线 OpenRouter,面向全球开发者免费开放 API 调用与体验。在全球技术圈引发了大范围的身份猜测,其从「单轮代码补全」到「智能体工程」的范式跃迁,奠定了国产开源模型的全球头部地位。3 月底发布的 GLM-5.1 则进一步强化了代码性能,8 小时长程工作的能力也让中国大模型真正冲过了由 Anthropic 编程可用基本线,本次 GLM-5.2 的出现把代码能力直接推进到世界一流模型的门口。
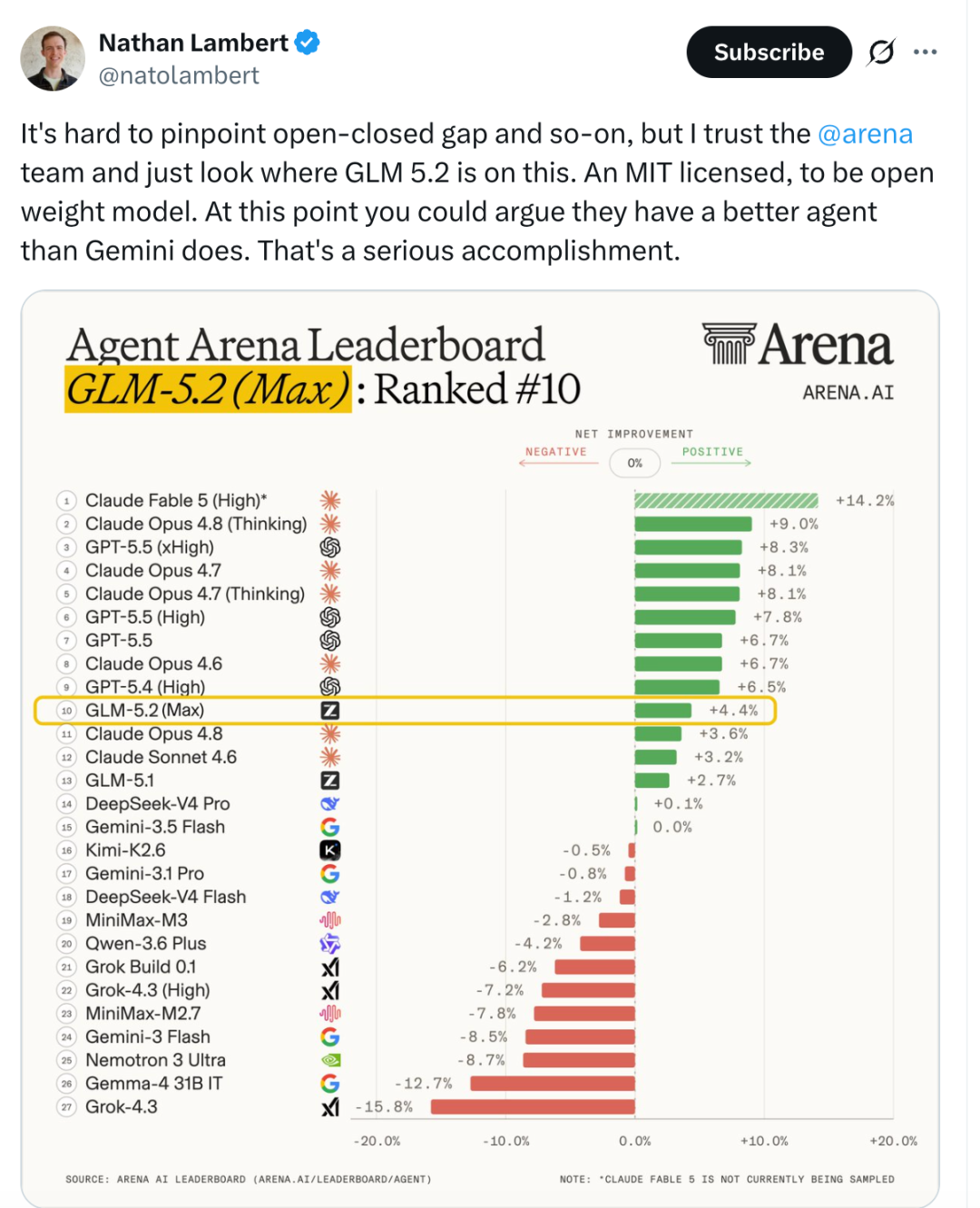
美国开源模型知名研究员 Nathan Lambert 评论称:“智谱 GLM-5.2 在当下在智能体能力超过了谷歌 Gemini,这是一份极具分量的成就”,这也意味着曾经垄断全球模型头部能力的谷歌,OpenAI,Anthropic “御三家” 铁三角,第一次出现了来自中国的模型企业。
中国开源生态,给予全球模型平权入场券
智谱 GLM-5.2 的发布是中国 AI 大模型阶段性发展成果的一个缩影。
马斯克关于中国大模型可能在 “一季度” 达到 Fable 水平的判断,真正值得关注的并不是具体时间点是否精确,而是它反映出全球市场对中国前沿模型追赶速度的重新估值。
美国财富对此报道称:“美国对 Fable 和 Mythos 的禁令证明了中国在科技自给自足方面所采取的更广泛举措是正确的。中国科技自给自足的步伐加快了。”
值得关注的是,上线首日,GLM-5.2 即完成与华为昇腾、平头哥、摩尔线程、寒武纪、昆仑芯、沐曦、海光、壁仞等国产算力平台的全适配;此前发布的国产大模型 DeepSeek V4 也已完成该类国产算力生态的全栈适配,这也意味着,来自中国的全栈开放生态,正在赋能全球 AI 产业实现开放包容、互利共赢的生态繁荣。
当美国闭源前沿模型越来越像一张需要审核资格的通行证,GLM-5.2 给出的答案是另一条路:前沿能力不一定只能封闭在少数平台里,也可以被开源出来,交给全球开发者重新构建。
全球大模型竞争的格局里,第一次出现了一个既接近顶级闭源体验、又选择开放路线的中国变量。
马斯克那个引发热议的 “2027 年一季度” 预测。从代际落后,到单点突破,再到如今在最硬核的智能体和长程复杂任务上 “上桌同博”,中国大模型把追赶的计价单位从 “年” 缩短到了 “月”。
从这个意义上说,GLM-5.2 不只是智谱的一次旗舰模型发布,而是国产大模型从 “追赶叙事” 进入 “同桌竞争” 的一个标志性节点。